Main Learnings:
- Version control systems and tools
- Git and GitHub
- Navigating and configurating the command line interface (CLI)

Table of Contents
- Benefits
- Version Control Systems
- Environments
- CI/CD
- Command Line
- Git & GitHub
- Branches
- Forking
- Remote vs Local
- Push and Pull
Introduction:
Version control is an essential concept for software engineering. It keeps track of your file history, a record of all modifications, and lets you go back to any previously saved version. Think of it as a Google Drive for your code. It also allows developers to seamlessly collaborate with each other, without messing other people's code up.
Benefits
There are numerous benefits that come with version control: revision history, identity, collaboration, automation, and many more. Revision history allows developers to see all changes to a project overtime, with the ability to revert to any previous state. This is particularly useful if the new code causes issues/bugs, because the team can go back to a prior working version. Each change comes with an identity, that displays who made the change, when the change was made, and what changes were made. Collaboration is made easier, since developers can use version control to review other's code, to ensure it is high quality. Many people are able to work on the project simultaneously, and can merge everyone's work at the end without breaking the codebase. Automated tests can be implemented, to ensure the code works as intended with every new change. While these are just some advantages of version control, there are many more, and version control is an essential component to every software project.
Version Control Systems
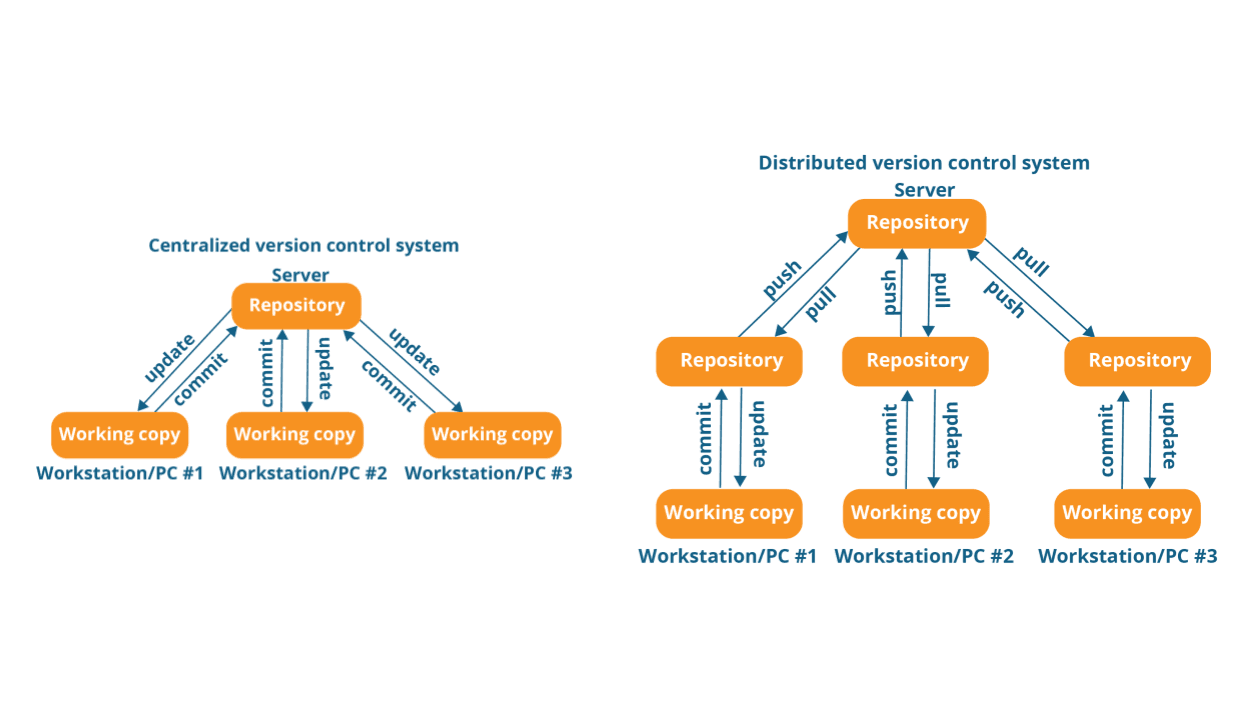
There are 2 main types of version control systems: centralized and distributed.
A centralized version control system (CVCS) has a main server and a client. The server is the respository, containing the version history of the code base. The client needs to pull the code from the server to their local machine, which makes a copy of the downloaded code. To make changes to the codebase, the developer has to push the changes to the server, so other developers can see them. The developer always has the latest version of the code.
Distributed version control systems (DVCS) is similar to the centralized model. The developers still need to pull code from the server, but instead of each local machine being a client, they also act like a server. The pull from the main server also pulls the verison history, so the developer is able to see the entire history of changes to the project on their local machine.
CVCS is considered easier to learn and enable more access control to the users. There can be authentication methods and restrictions in place, only allowing certain users to perform certain actions. However, it is considered slower since a server connection is required in order to perform actions. In DVCS, no server connection is required to add changes or view file history. It essentially feels like you have the server downloaded on your local machine. It is faster than CVCS, because CVCS heavily relies on the server; if the server slowed down or stopped working, development had to stop. However, in a DVCS, a connection is still required to push or pull changes from the main server.
Environments
To ensure a great user experience, development teams need to verify the code they are releasing does not cause any bugs. Typically, teams will set up environments to test and verify their code, to identify any potential issues before publishing their code.
The staging environment mimics the production environment (public user experience). The more similar the staging and production environments, the more accurate the testing becomes. This is because they are then essentially the same, just varying in who has access to the staging environment. It can also be used as a beta trial for new features.
The production (live) environment is what public users see and interact with. Prior to this stage, code problems should be minimized due to rigorous testing in the staging environment. Downtime for the product typically impacts the revenue and reputation of the service. Users will not be able to access the product, and frequent downtime due to bugs causes distrust amoung its users. Cyber-security considerations need to be in place, to prevent the data of the application.
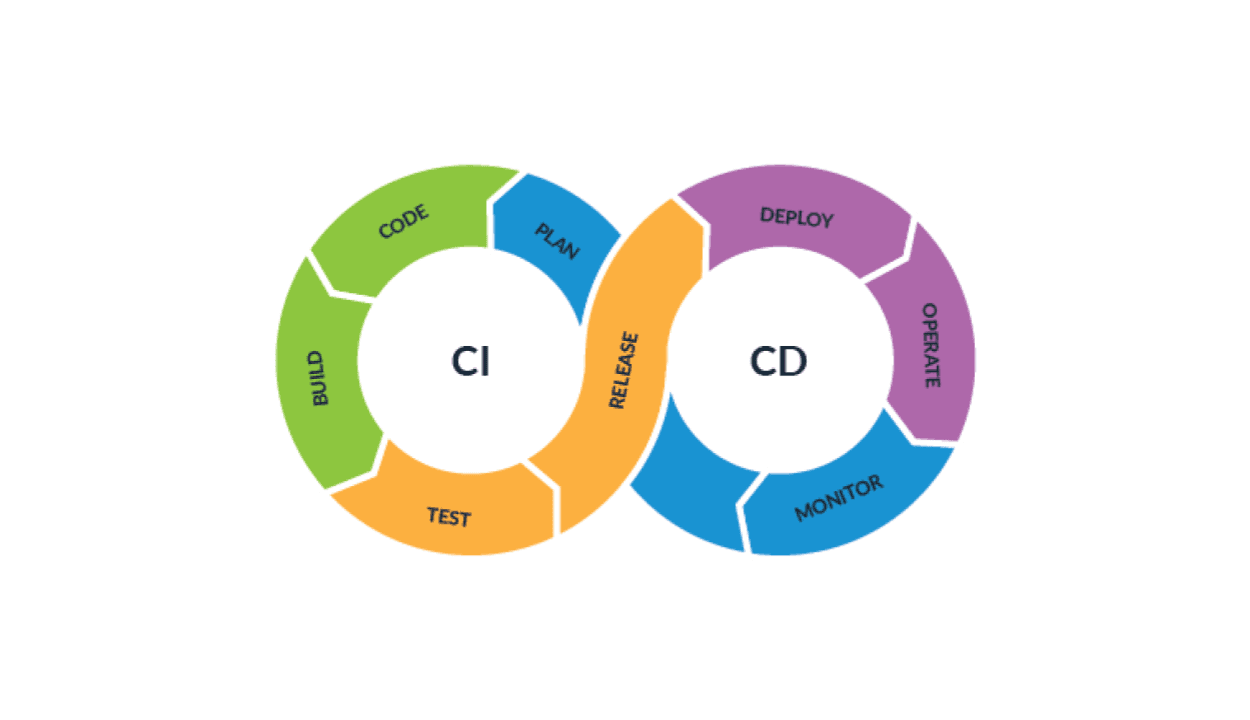
CI/CD
Continuous Integration (CI) means automating code changes into a single main stream. When the workflow consists of small frequent changes, this reduces merge conflict in the code. CI compiles the project automatically and runs tests on each iteration to verify the codebase is working as intended to prevent regressions.
Continuous Delivery (CD) extends CI. Once the changes are successfully merged into the main stream, a CD system automatically bundles the application and prepares it for actual deployment.
Continuous Deployment (also apart of CD) extends CD. It frequently releases the software to the customers. Typically, the developers create a testing environment that the development build has to pass, and then it is deployed to the live environment for customers to use.
Command Line
People can seemlessly interact with computers on a daily basis through a graphical user interface (GUI), since it is visual and intuitive to use. However, there are limitations to using a GUI for developers, since it is considered less powerful and slower than the command line interface (CLI). The command line enables the user to perform various advanced actions that is not possible with the GUI. Below are a few common CLI commands (note: variables can be any name):
| Command | Usage | Example |
|---|---|---|
cd x | Change Directory | cd dir |
cd .. | Parent Directory | cd .. |
mkdir x | Make Directory | mkdir new_dir |
touch x | Create New File | touch ex.js |
code x | Open File in VS Code | code ex.js |
ls | List Contents | ls |
man x | Command Manual | man mkdir |
pwd | Path to Current Directory | pwd |
Flags are optional parameters we can give to a command. They change the behavior or provide extra functionality of that command. For example, ls -a is simply the ls command with the -a flag. Instead of only printing out the contents, it additionally prints out hidden content. The ls -l command prints out the directory contents in a list with the read/write permissions and owners.
A powerful feature inside CLIs is the "pipe" command, which is used with this symbol: |. It enables you to combine multiple commands together into a single line, by using the output for one command as the input for another command. This is known as "piping".
Redirection in a CLI provides control over the input, output and error message of a command. There are 3 input/output (IO) redirections:
standard input (stdin), standard output (stdout), and standard error (stderr)
. The command-line shell keeps references for the IO using numbers. 0 represents standard input, 1 represents standard output, 2 represents standard error.To interact with computers, we provide input. This can be the keyboard, mouse, microphone, etc. Certain commands also require input for them to work. For example, the cat command concatenates and displays the content of the file, and needs some sort of file as an input for it to work. We can use the input redirection symbol, < to redirect an input into the cat command. Below is an example of it in use:
bash
cat < file.txt
# takes file.txt as input for cat command
# prints content of file.txt to the consoleEvery command in Unix has an input source and output source. We can actually redirect the output source to wherever we desire, using the > symbol. For example, we can record the entire output of the ls command in a file.
bash
# assume current directory has "file.txt" file and "coding" folder
ls > result.txt # stores ls output into result.txt
less result.txt # shows result.txt contentThe last possible redirect is the standard error. This happens when an unexpected error occurs when running a command. The symbol is 2>. It is similar in spirit to the output redirect, but instead only contains the error if it does occur. It can be used in conjunction with the output symbol (>) as a "fail-safe" option, to ensure the command still runs. If it can be executed, the appropiate output will be used, otherwise if an error occured, then the error will be used. Keep in mind, if it is used with the output redirection symbol, it is then denoted as 2>&1.
bash
# assume /notExist folder doesn't exist
ls /notExist > error.txt # prints error message to console: "ls: /notExist: No such file or directory"
ls /notExist 2> error.txt # stores error message in error.txt
less error.txt # shows error.txt content: "ls: /notExist: No such file or directory"
ls /notExist > stdError.txt 2>&1 # stores /notExist content if /notExist does exist, otherwise stores error message (fail-safe method)Global regular expression print, also known as grep, is used to search and filter text in files or data streams. It matches the provided expression and then prints the results to the terminal. The basic usage is grep term file, where term is the text being searched for and file is the file or data stream that is being searched in.
text
Samie
Samanda
Ashley
Jennifer
Joshua
Amanda
Daniel
David
James
Robert
John
Joseph
Jasamine
Ryan
Brandon
Jason
Justin
Sarah
William
Rosabash
grep Sa file.txt
# output:
#Samie
#Samanda
#Sarah
grep sa file.txt
# output:
#Jasamine
#Rosa
grep -i Sa file.txt # ignore casing
# output:
#Samie
#Samanda
#Jasamine
#Sarah
#Rosa
grep -w Sa file.txt # exact matches only
# output:
Git & GitHub
Git is a version control system that tracks changes to projects. Git is incredibly popular due to its performance and reliability. GitHub is a web plaform that stores all the files and folders to allow developers to collaborate, similar to Google Drive.
There are 3 Git workflow states: modified, staged, committed. The modified state is when any file has been modified in any way inside the repository. Git know the file has changed itself, but does not track it in terms of saving it to the version history. In order for a file to be tracked, it must be added to the staged area, where then Git tracks changes to the file. The committed state is a savepoint for the file and entire repository, keeping a copy of the repository at the time of commit. The savepoint is added to the version history of the repository.
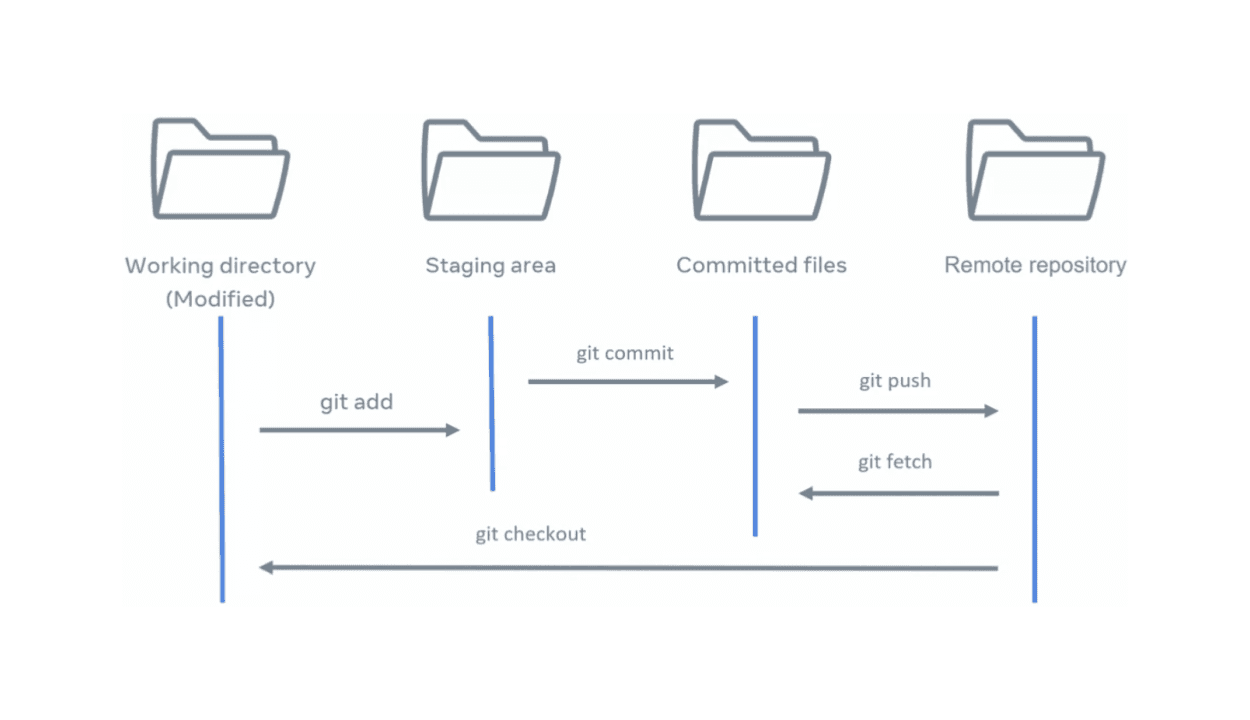
git status displays the current state of your working directory. It shows the current branch, modified files, untracked files, and files staged for commit. git add x lets Git know that file x should be tracked, and will be apart of the next code commit. To remove it from the staged state and not be in the next code commit, use the command git restore --staged x to restore file x. In order for the code to be committed on your local machine, run the command git commit -m "x", where x is the message that will go along with the commit. For the changes to be available on the main repository, run git push. More on push and pull in a later section.
bash
git status # prints current git state
touch file.txt # adds file
git add file.txt # Git now tracks file.txt
git restore --staged file.txt # Git no longer tracks
git add file.txt # Git again tracks file.txt
git commit -m "Commit message" # commits on local machine with message
git push # pushes to repositoryBranches
Branches are a different commit version than the main branch and other repository branches that can be actively developed on, isolated from each other. Branches are commonly used to develop features and experiment without affecting the main codebase, and allow for different teams to work on code without affecting each other. If they decide the code is good, they can merge it with the main branch. git branch lists all the branches in the repository. git checkout -B newBranch moves you to the newBranch branch that was newly created.
Feature branching is a common technique used throughout software development. Feature branching means creating a new branch from the main branch, and develop on that branch until the feature is complete. Once the feature is complete, it can then be pushed to the main branch, where then it is peer reviewed to ensure the code is acceptable. If fellow developers consider it to be good code, it can then be approved to merge onto the main branch.
Forking
While branching creates a new branch from the same repository, and each team member works on that same repository, Forking creates a entirely new independent repository. Forking essentially creates a copy of the repository and grants you ownership of that copy. The forked repository and original repository are entirely disconnected from each other, so changes are unlinked to every forked repository. If someone wanted their code changes to be added to the original repository, the owner would need to review and accept your pull request.
Remote vs Local
The internet enables wireless and fast data transfer. Local code is the code only available on your local machine, only accessible to you. Remote code refers to code that is accessible via URI by numerous people, as long as they have permission to access it. This can be something like GitHub. In order to get code from the remote repository to your local machine, if it is the first time, the repository needs to be cloned. After that, the local machine only needs to pull to get the latest changes. The user can make changes and then push them back to the server. Other developers cannot see those new changes until they pull from the server.
Push and Pull
Recall that to check the current status of your project on your local machine, run git status. It is always important to check which branch you are on before pushing or pulling from the codebase. To pull the latest server code, perform the git pull command. It is best practice to perform this command prior to pushing code to the server, since it will reduce the chance of a merge conflict. Remember, git push branchName pushes the code to the branchName branch.
Conflicts can occur when developers merge branches together but have different changes on the same lines/pieces of code. While Git tries to auto-merge code changes, conflicts need correction by the developer. Git marks conflicting lines with markers, which then the developer has to review and modify, ultimately deciding the final changes. The conflicting lines are marked with <<<<<<< to indicates the start of the conflicts, ======= separates the branch you're trying to merge onto from the commit you're trying to merge, and >>>>>>> indicates the end of the conflict. Below is an illustration of what a conflict might look like in VS Code:
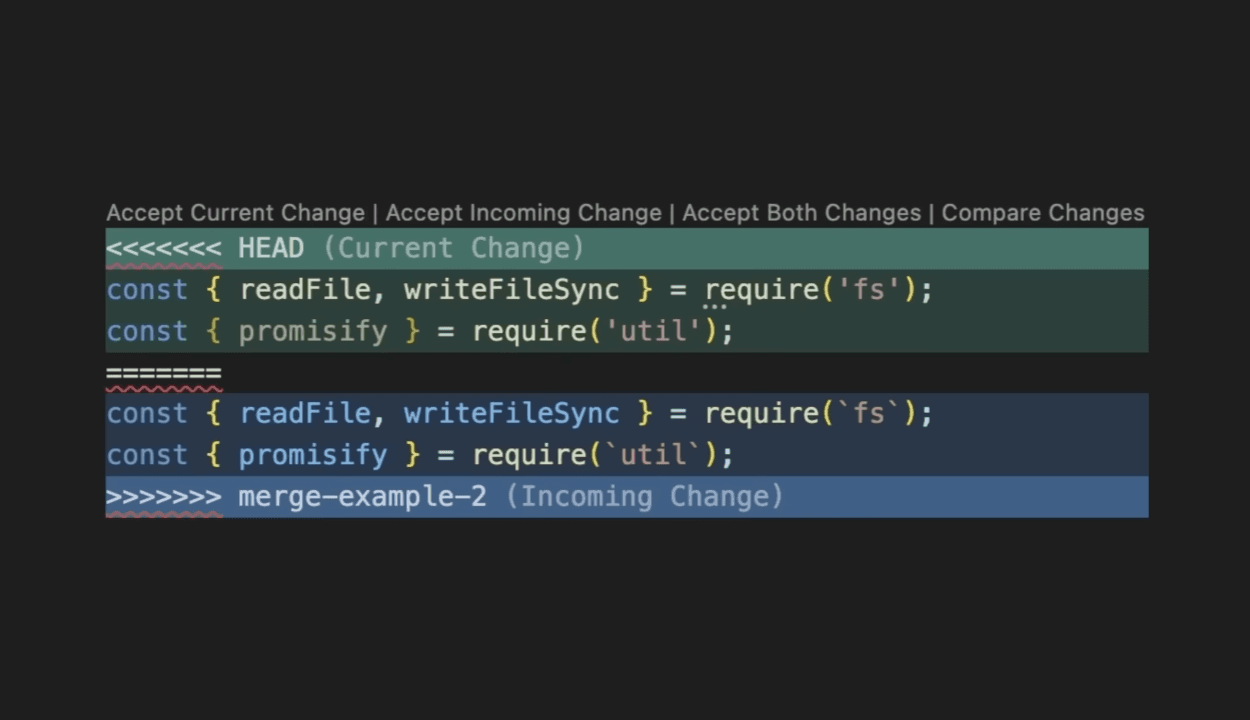
Current Change represents the your changes, while Incoming Change represents the changes made in the branch you're trying to merge to. There are a few options to resolve the merge conflict: Accept Current Change, Accept Incoming Change, Accept Both Changes, and Compare Changes. Accept Current Change and Accept Incoming Change are self-explanatory; the chosen change will be accepted, and the other will be rejected. Accept Both Changes causes all the lines of code to be in the codebase. Compare Changes gives a side-by-side view of the incoming and current changes, to better understand where it lies in the code and compare the different versions. VS Code has numerous additional features to help resolve merge conflicts, and you can find a full tutorial on merge conflicts here.